With several AI solutions existing on the market, the question arises: how to choose the best one for your mammography practice? Which factors should you consider when comparing their performances? Here are five actionable pieces of advice on how to evaluate AI’s performance.
Forget about accuracy
It’s so easy to be seduced by attractive marketing messages like “our AI detects breast cancer with 96-99% accuracy”. But is accuracy the right metric to assess? A study has shown that it is difficult to determine if the AI tools have high accuracy and are clinically applicable, due to a large degree of variation in methodology and quality of datasets.
For instance, accuracy is not a valid metric when faced with imbalanced datasets. These datasets contain a significant disproportion among the number of cases of each class, with a biased distribution towards a particular class.
Let’s have a look at a formula quantifying the accuracy of a breast cancer screening AI.
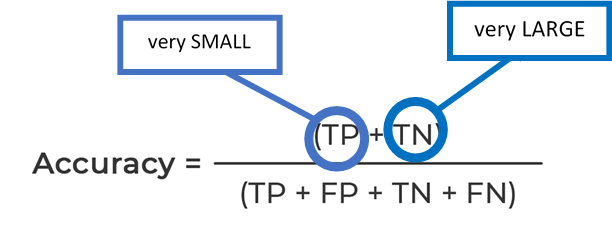
*TP – true positives, TN – true negatives, FP – false positives, FN – false negatives
High accuracy results can be easily achieved when using a dataset with a very small number of true positives (cancer cases) and a very large number of true negatives.
Advice #1: always look at the dataset when analyzing accuracy.
Do not trust AUC ROC blindly
In breast cancer screening, the AUC (Area Under The Curve) ROC (Receiver Operating Characteristics) indicator tells us how well an algorithm is capable of distinguishing between mammograms containing and not containing cancers.
AUC ROC is a valid figure of merit on representative datasets of the problem the AI tries to solve. Engineers usually use it to evaluate different versions of the same algorithm. However, it must be used on the same dataset, so two versions can be compared fairly between themselves. And it also must be representative of the use case you target to avoid surprises in a clinical environment, for mammography the most relevant is probably a screening population.
Thus, an AUC of a dataset containing TP, FN, TN, and FP cannot be compared to an AUC of an algorithm evaluated on a simpler dataset without FN, even if both datasets have the same number of total cases. Definitions can also vary between dataset: is an FP confirmed by biopsy or by follow-up exams? Does a TN include a fair amount of BI-RADS 1 and 2?
Further, the performance itself cannot be used to judge a product—an algorithm with a low standalone AUC can show better performances with radiologist and AI combined than another algorithm with a higher standalone AUC. This is explained by the quality of the product in terms of user experience: relevance of information showed to the user and calibration of the output.
Advice #2: when comparing algorithms, AUC should not be used without considering the dataset composition.
Evaluate MRMC study results
Results of multiple reader-multiple case studies (MRMC) of different software offer an interesting perspective but cannot be compared directly.
For instance, you should pay attention to the experience level of participants who interpret cases. Surely, an AI solution will be more helpful for general and young radiologists than for breast fellowship-trained radiologists. Whereas it will be more challenging to augment the reading performance of specialized breast fellowship-trained physicians.
The protocol used to measure the different metrics should also be questioned. Some MRMC studies in the literature have readers reading a screening DBT in 25 sec without AI in average, with some going down to 10 sec with AI, knowing the uncompressing time to discover a tomosynthesis, one could question the transferability of this results in clinical practice.
When conducting a reader study to evaluate MammoScreen®’s performance, we chose 14 breast fellowship-trained radiologists. MammoScreen® was helpful even to such experts.
Advice #3: always question study results.
Meaningful metrics for your practice
In mammography screening, there are two main metrics to look at: the cancer detection rate and the recall rate. When evaluating AI for mammography, you should assess its impact on these metrics.
For instance, MammoScreen® is capable of detecting 27% of missed cancers 1 year earlier and 21% of missed cancers 2 years earlier. This was shown in a study with 16,004 US patients including 408 cancers.
Even though recalls are not a bad thing, it’s important to ensure that patients are recalled for a serious reason. For example, our multi-reader multi-case study showed that MammoScreen® reduced the recall rate up to 30% (with an increase in CDR). MammoScreen® can also reduce by 25% the number of unnecessary biopsies for calcifications.
Advice #4: check the metrics that matter to you.
Advice #5: Test AI yourself
A very important metric but difficult to evaluate with the literature is the confidence you might have in the software. A software with too many false positives will not be useful, that is the main default of CAD. Conversely with a software not sensitive enough you will not be confident enough to tell if a case is benign if the software hasn’t detected anything (because some malignant lesion might have been missed). Only a well calibrated software can resolve this issue. For this, only one option: test it yourself. To do that:
✓Create your own dataset – pick 20-30 cases of different levels of difficulty. If you have cases containing missed cases, don’t forget to include them.
✓Ask different vendors to run the algorithm on your dataset.
Keep in mind the AI is not seeing the additional exams but is only assessing mammograms – it’s a tougher job, so do evaluate fairly.
✓You need to have a feel for the user experience (UX) and validate it in practice – ask the vendor for a short trial.
✓Look at the software integration process. Is it a seamless way of working? Can it be easily deployed in other facilities?
Opt for software with a zero-click workflow. It will help you save your time: it might take a while to click on the CAD marks to evaluate them.
Sign up for a free MammoScreen® demo and see for yourself how you can benefit from our AI.